スペクトラルクラスタリング入門
2017.11.2

こんにちは、データサイエンスチーム tmtkです。
この記事では、スペクトラルクラスタリング(Spectral Clustering)について説明します。スペクトラルクラスタリングについて、具体的には、
- スペクトラルクラスタリングとは
- 行列の固有値分解によるグラフの連結成分分解の説明
- スペクトラルクラスタリングのアルゴリズムと計算例
- 関連する話題
を説明します。
スペクトラルクラスタリングとは
スペクトラルクラスタリングとは、クラスタリングアルゴリズムの一つです。クラスタリングは機械学習の方法のうち、教師なし学習に分類されます。データが与えられたとき、正解データなしでデータを複数の集団に分ける方法です。
スペクトラルクラスタリングの特徴は、データからグラフを生成し、グラフの連結成分分解を応用してクラスタリングするところです。クラスタリングアルゴリズムとして古典的なものに、KMeansやGaussian mixture modelがあります。KMeansやGaussian mixture modelはクラスタの中心点からの距離に基づいてクラスタリングを行いますが、スペクトラルクラスタリングでは連結性に注目してクラスタリングを行うため、KMeansやGaussian mixtureではうまくクラスタリングできなかったようなデータをうまくクラスタリングできることがあります。
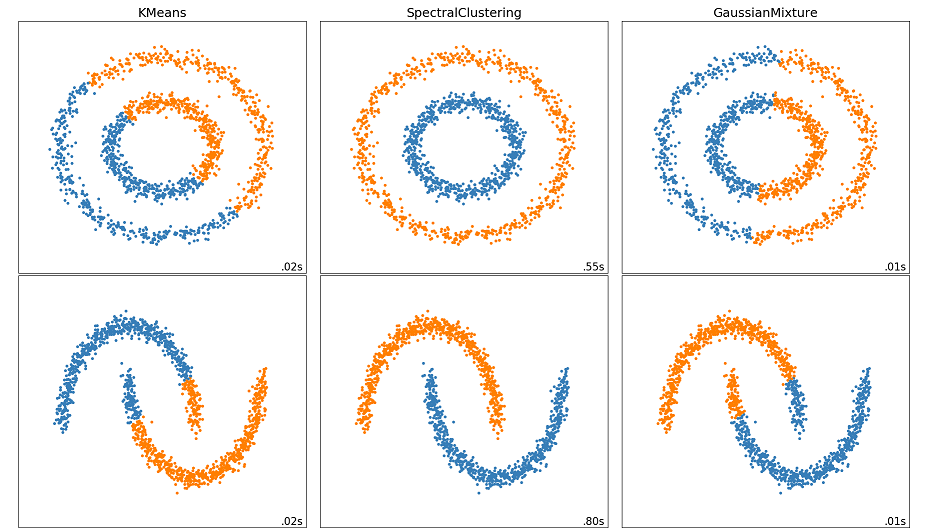
(KMeans, Spectral Clustering, Gaussian Mixtureの比較。画像はscikit-learnのページのプログラムを改変して作成しました。)
【事例集】AIや機械学習によるビッグデータ活用をしたい方にオススメ!

「AIによるキャスト評価システムの構築」「データ分析基盤の運用費用9割削減」など、AWSを利用したAI、機械学習の成功事例をご紹介します。
行列の固有値問題によるグラフの連結成分分解
スペクトラルクラスタリングのアルゴリズムを説明する前に、その基礎として、行列の固有値問題によってグラフの連結成分分解を行う方法を説明します。
いま、正の重みつき無向グラフ
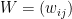
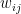


たとえば、頂点1と頂点2が重み100の辺でつながっていて、頂点3と頂点4が重み20の辺でつながっているグラフ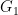

隣接行列
になります。
隣接行列
で定義します。グラフ
で定義します。
グラフ

になります。
このとき、次の定理が成り立ちます。




定理
グラフ



証明
線形代数からわかります。詳細は参考文献を参照していただくとして、ここでは証明の概略を説明します。
まず、具体的に計算すると、対称行列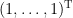
この定理を前の例で計算してみましょう。
が
すなわち、
が成り立ちます。このことから、固有値0に属する固有空間は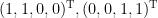
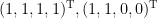
ここから、グラフの連結成分分解を得るには次のようにします。まず、この基底を並べて行列
をつくります。この行列を構成する行ベクトルをそれぞれ見ると、1行目と2行目がどちらも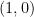
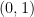

このようにして、グラフの連結成分を、行列の固有値問題を解くことによって得ることができます。
以上の議論をまとめると、以下の手順によって、グラフの連結成分分解ができることがわかります。

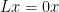
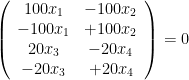

- グラフから隣接行列表現
- unnormalized graph Laplacian
を計算する。
- 基底ベクトルを並べて行列
を作る。
- 行列
のi行目とj行目の行ベクトルが等しければ、頂点
と
は同じ連結成分に属し、さもなくば違う連結成分に属している。
スペクトラルクラスタリングのアルゴリズムと計算例
スペクトラルクラスタリングのアルゴリズムは、上に説明したグラフの連結成分分解を応用したものです。具体的には、以下のようなアルゴリズムで行います。
いま、クラスタ数
- データからグラフを構築する。
- グラフから隣接行列表現
- unnormalized graph Laplacian
- 固有ベクトルを並べて行列
- 行列
- K-meansの結果、i行目が入ったクラスタを頂点
連結成分分解との相違点は、データからグラフを構築するステップが必要であるところと、連結成分分解のようにi行目とj行目が厳密に等しかったり異なったりしないために、K-meansなどを使う必要があるところです。
具体的に計算をしてみましょう。前のグラフとは少し変えて、次の連結なグラフを考えます。このグラフを

このグラフのunnormalized graph Laplacianは
と計算でき、コンピュータを用いて計算すると、その固有値は
で、対応する固有ベクトルは、有効数字2桁で四捨五入すると、
です。固有値の小さいほうから固有ベクトルを
この4つの行ベクトルをK-meansでクラスタリングしたら、1行目と2行目の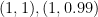

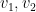

同様に、
の4つ行ベクトルを3クラスタにK-Meansでクラスタリングすることになります。この場合は

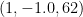


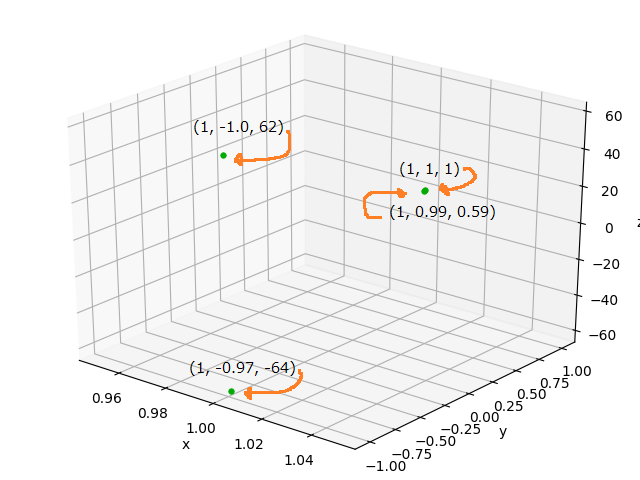
(よく見ると2点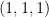

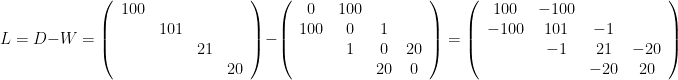

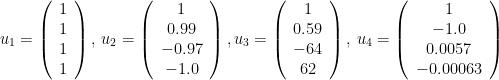
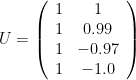

関連する話題
スペクトラルクラスタリングではまずデータをグラフに変換します。グラフへの変換の仕方はいろいろあり、
- ε近傍法
- k近傍法
- 全結合法
などがあるようです。ユークリッド空間上の距離関数を

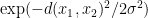
また、graph Laplacian
や
などが使われるようです。どちらも

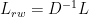
まとめ
- グラフの連結成分分解を、行列の固有値問題に還元することができます。
- 固有値問題による連結成分分解を応用したクラスタリングが、スペクトラルクラスタリングです。
【事例集】AIや機械学習によるビッグデータ活用をしたい方にオススメ!
「AIによるキャスト評価システムの構築」「データ分析基盤の運用費用9割削減」など、AWSを利用したAI、機械学習の成功事例をご紹介します。
参考文献
- A Tutorial on Spectral Clusteringがこの分野のテキストの決定版のようです。本記事もこの資料を大いに参考にしています。
- Comparing different clustering algorithms on toy datasets – scikit-learn documentationクラスタリングアルゴリズムを比較する画像が面白いです。
テックブログ新着情報のほか、AWSやGoogle Cloudに関するお役立ち情報を配信中!
Follow @twitter
データ分析と機械学習とソフトウェア開発をしています。 アルゴリズムとデータ構造が好きです。
Recommends
こちらもおすすめ
-

機械学習理論の考え方をゲームを使ってみてみる
2016.1.12
-

Pythonで実装する画像認識アルゴリズム SLIC 入門
2018.2.13
-

機械学習 曲線フィッテングについて おまけ?編
2016.4.28
-

基礎からはじめる時系列解析入門
2019.2.22


Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 8 %割引になる!
『AWSの請求代行リセールサービス』
2023.01.15